Ecosystem Pipeline
We have developed the Ecosystem Simulator to make the natural environment of our game world realistic. However, we need a lot more than just an executable of the Ecosystem Simulator.
The ecosystem in the game is not static at all; it is an ever-changing environment. Players walk around to harvest plants and other natural resources and the system tries to replenish those, not necessarily at the previously existed locations, but in anywhere appropriate. This is where the Ecosystem Simulator comes into play; it takes the current environment as an input, performs some calculations, and produces the outcome.
Now, imagine the environment on which the game server code is deployed. We certainly have more than (a lot more than) a single machine. Running the Ecosystem Simulator entails a variety of challenges due to the sheer volume of computations.
We had two major goals in our mind:
- Contain the runtime in a constant time (O(1)).
- Keep the cost low.
We wanted to make the simulator runtime independent of the size of the world. In other words, the runtime of the simulator remains unchanged even if we run the simulator on bigger lands.
Cost saving is another key aspect. There is no need to run the simulator for the entire game world; if some part of the world remains unvisited, we presumably do not need to run the simulator on that part as no one is even looking at it. One of the key philosophies of our game server architecture is "no audience, no play."
The Architecture
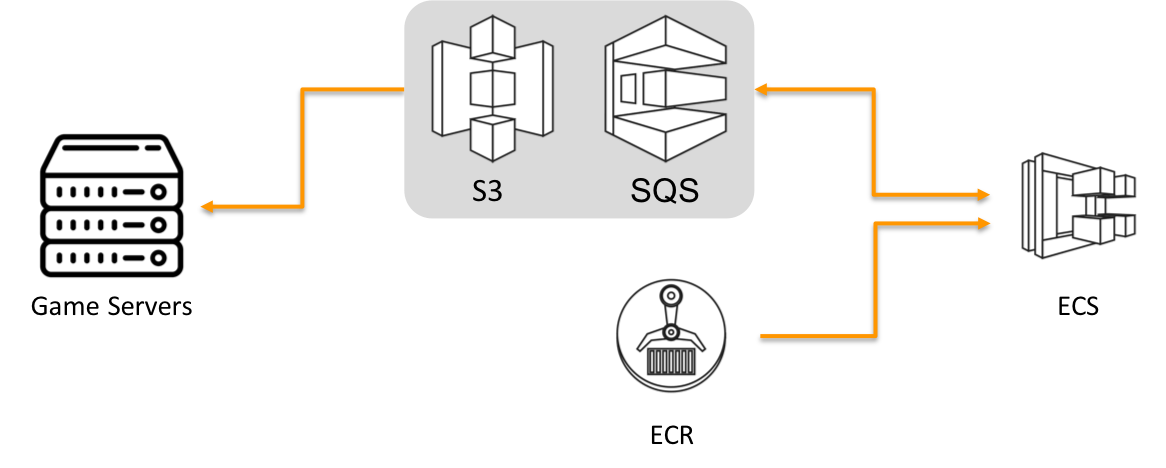
In summary, this is an overview of the architecture that we have settled on. This may not be obvious at first glance, but we will dive into each component and explain what kind of technical problems we faced and how we came up with plausible solutions.
The Environment
- The Ecosystem Simulator is packaged as a Docker image.
- The Docker image is hosted on Amazon ECR.
- The simulator will be run on Amazon ECS.
Scalability & Automation
Amazon S3 Bucket Replication
Amazon Simple Queue Service (SQS)
Player activities are something we can hardly predict accurately. Sometimes a lot of players move around and destroy the forest, and sometimes not many players are around.
We have provisioned a certain number of ECS agents, which determines our compute capacity. When we go over the limit, it will not be able to run any additional tasks and we are going to have missing tasks, which translates into un-replenished, empty spots in the game world.
To alleviate this problem, we brought the SQS into the picture to act as a buffer between the producer and the consumer. Here, the producer is the game server and the consumer is the ECS cluster. Rather than having the game server directly invoke an ECS task, it inserts a request message in the queue and a Lambda function processes it subsequently. We need Lambda because SQS messages cannot invoke an ECS task by themselves.
In distributed systems, two things are very difficult to achieve:
- Deliver messages exactly once
- Deliver messages in order
In our case, the exactly-once semantics is relatively less of concern and the throughput was a lot more important, so we decided to go with the standard queue.
To make a side note, those problems can be seen as a mathematical problem, rather than a software engineering problem. If your operations are communicative, out-of-order messages in SQS won’t affect the final outcome. Likewise, if your operations are idempotent, duplicated messages won’t cause any damage.
In our case, the replenish operations are executed on a chunk basis, so the order in which they are carried out doesn’t really matter.
And the replenish algorithm is designed in a way that the marginal difference after each iteration asymptotically approaches to zero. This isn’t exactly a purely idempotent function in a mathematical sense, but in practice, executing the replenish operation twice instead of once produces an acceptable outcome. It looks ‘good enough’. Message duplication is an exceptional case rather than an average case, we decided not to worry about it too much. So the standard queue was a more reasonable choice for us.
Chunks

A tile is the finest granularity for object placements. A single object occupies one tile. A chunk is a pack of 16x16 tiles. A chunk is a basic unit for a workload. For example, our game server loads terrain data by chunk, and the Ecosystem Simulator does its job on a chunk basis. By dividing up a large island in small chunks like this, we can process any task in parallel, and most importantly, we can finish the tasks in a fixed amount of time, regardless of the size of the island, as long as enough compute power is provided and there are no inter-dependencies between tasks.
Amazon Elastic Container Service (ECS)
(TODO: Write this section)
Auto Scaling
(TODO: Write this section)
Public Speeches
This article is a simplified version of the following public speeches. For more detailed information, you may consult these:
- AWS re:Invent 2017: Automating Mother Nature
- Nexon Developers Conference 2016: Automated Game Terrain Management for Durango